Agent Trace Evaluation with TruLens Scorers in MLflow

MLflow's third-party scorer framework already supports LLM-as-a-judge evaluations from DeepEval, RAGAS, and Phoenix, an ecosystem with 18M+ monthly PyPI downloads. We're excited to announce the TruLens integration as we continue our efforts to expand support for various third-party evaluation frameworks.
An agent doesn't just produce an answer. It makes a plan, picks tools, executes a multi-step workflow, and adapts when steps fail. A correct final answer can mask a flawed plan, redundant tool calls, or broken reasoning along the way. To catch those problems, you need to evaluate what happened inside the execution trace, not just what came out the other end.
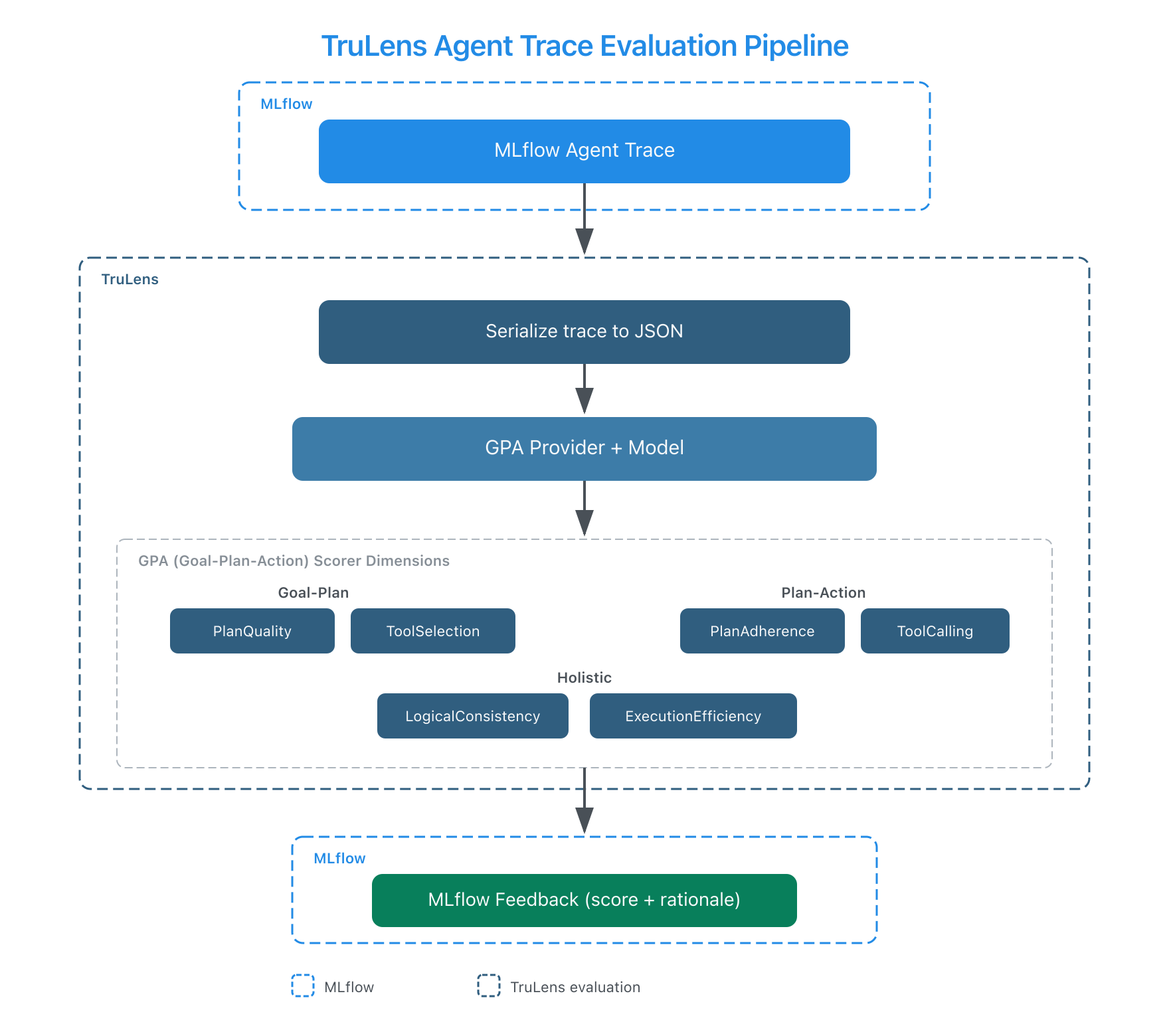
The integration adds 10 scorers that bring the Agent GPA framework to MLflow. You pass an MLflow trace, and the scorer reads the full span tree (plans, tool calls, intermediate outputs) to evaluate agent behavior. MLflow already supports trace-based judges and agentic metrics from DeepEval and RAGAS. TruLens adds a structured three-dimensional lens (Goal, Plan, Action) developed by the TruLens team at Snowflake.
The Agent GPA Framework
GPA stands for Goal-Plan-Action, and it evaluates three alignment dimensions in an agent's execution:
Goal-Plan alignment asks: did the agent make a good strategy? An agent that gets the right answer by brute-forcing every available tool has a Goal-Plan problem even if the output looks fine.
PlanQualitychecks whether the plan decomposes the goal into feasible subtasks.ToolSelectionchecks whether the agent picked the right tools for each subtask.
Plan-Action alignment asks: did the agent follow through? Did it skip steps, reorder things, or repeat work?
PlanAdherencechecks whether the agent's actual actions match its stated plan.ToolCallingchecks whether function calls are valid, with correct parameters and complete inputs.
Holistic alignment looks at the trajectory as a whole.
LogicalConsistencychecks whether each step is coherent with prior context and reasoning.ExecutionEfficiencychecks whether the agent reached the goal without redundant calls.
On the TRAIL/GAIA benchmark, GPA judges identify 95% of human-labeled agent errors (267/281), compared to 55% for standard judges that only look at final outputs. That 40-percentage-point gap is what you leave on the table when you only evaluate the answer.
The integration exposes six agent scorers covering the three GPA dimensions:
| Scorer | Alignment | What it checks |
|---|---|---|
PlanQuality | Goal-Plan | Does the plan decompose the goal into feasible subtasks? |
ToolSelection | Goal-Plan | Did the agent pick the right tools for each subtask? |
PlanAdherence | Plan-Action | Did the agent follow its plan, or skip and reorder steps? |
ToolCalling | Plan-Action | Are tool calls valid with correct parameters and complete inputs? |
LogicalConsistency | Holistic | Is each step coherent with prior context and reasoning? |
ExecutionEfficiency | Holistic | Did the agent reach the goal without redundant calls? |
Pass a trace and the scorer handles the rest. Under the hood, the integration serializes your MLflow trace to JSON and passes the full span tree to TruLens' provider, which evaluates each dimension with chain-of-thought reasoning. You get back a score and a rationale explaining what it found.
How Trace Evaluation Catches What Output Evaluation Misses
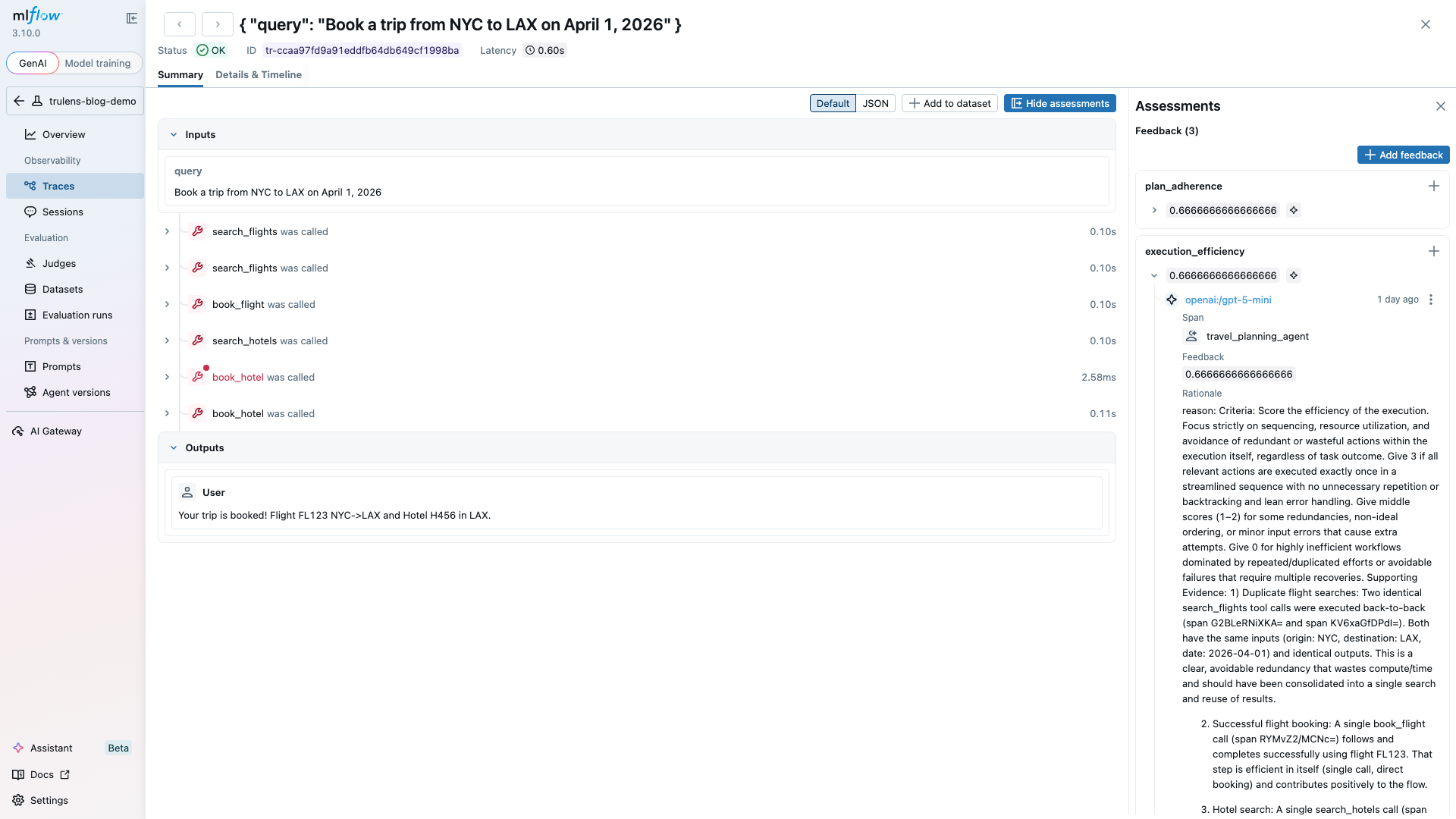
Here's a concrete scenario. Say you have a travel-planning agent that should: (1) search for flights, (2) check hotel availability, (3) book both. The agent returns "Your trip is booked!" and it looks correct. But the trace tells a different story:
Span 1: search_flights("NYC", "LAX", "2026-04-01") -> 3 results
Span 2: search_flights("NYC", "LAX", "2026-04-01") -> 3 results <- duplicate
Span 3: book_flight(flight_id="FL123") -> confirmed
Span 4: search_hotels("LAX", "2026-04-01") -> 2 results
Span 5: book_hotel(hotel_id=None) -> error
Span 6: book_hotel(hotel_id="H456") -> confirmed
Output-only evaluation gives this a pass. The trip got booked. Trace-level evaluation catches three problems:
- ExecutionEfficiency: redundant flight search (Span 2 duplicates Span 1)
- ToolCalling:
book_hotelcalled withNonebefore retry (Span 5) - PlanAdherence: the agent booked a flight before searching for hotels
Combining Agent and RAG Evaluation
You can mix agent trace scorers, RAG scorers, and scorers from other frameworks in a single mlflow.genai.evaluate() call. The trace scorers read the span tree, while RAG scorers like Groundedness extract context from retrieval spans in the trace automatically. All scorers support a model parameter for choosing your LLM provider (OpenAI, Anthropic, or any LiteLLM-compatible provider).
import mlflow
from mlflow.genai.scorers.trulens import (
Groundedness,
PlanAdherence,
ExecutionEfficiency,
)
from mlflow.genai.scorers.phoenix import Hallucination
traces = mlflow.search_traces(locations=["..."])
results = mlflow.genai.evaluate(
data=traces,
scorers=[
# Agent behavior (reads the full span tree)
PlanAdherence(model="openai:/gpt-5-mini"),
ExecutionEfficiency(model="openai:/gpt-5-mini"),
# RAG quality (extracts context from retrieval spans)
Groundedness(model="openai:/gpt-5-mini"),
# Content quality (Phoenix)
Hallucination(model="openai:/gpt-5-mini"),
],
)
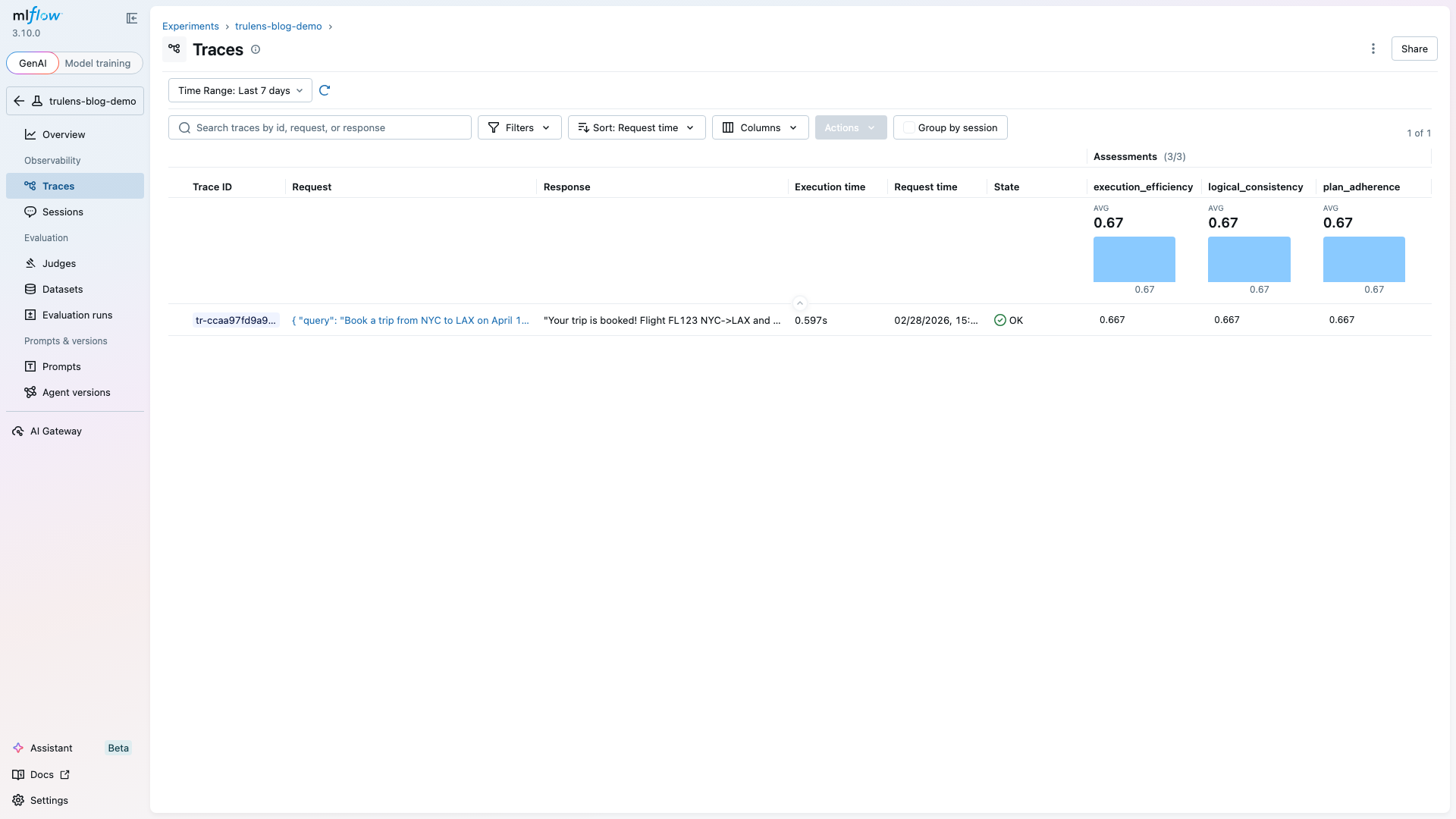
Each scorer runs independently and writes results to the same experiment. Results land in the MLflow assessment table alongside any other evaluation results.
Getting Started
pip install mlflow>=3.10.0 trulens trulens-providers-litellm
from mlflow.genai.scorers.trulens import PlanAdherence, Groundedness
# Agent trace scorer
scorer = PlanAdherence(model="openai:/gpt-5-mini")
feedback = scorer(trace=my_agent_trace)
print(feedback.value) # "yes" or "no" based on threshold
print(feedback.rationale) # Chain-of-thought reasoning
# RAG scorer (extracts context from retrieval spans in trace)
scorer = Groundedness(model="openai:/gpt-5-mini", threshold=0.6)
feedback = scorer(trace=my_rag_trace)
print(feedback.value) # "yes" or "no"
print(feedback.rationale) # Why it passed or failed
print(feedback.metadata["score"]) # 0.85
Resources
- Third-Party Scorers Overview
- Trace-Based Judges
- Agent GPA Framework (Snowflake Engineering Blog)
- Trace-Aware Agent Evaluation for MLflow (Snowflake Engineering Blog)
- Agent GPA Paper (arXiv)
- TruLens Documentation
- Introducing DeepEval, RAGAS, and Phoenix Judges in MLflow
Provenance
I contributed the TruLens integration (PR #19492) to MLflow's open-source third-party scorer framework, adding 10 scorers: 4 RAG metrics and 6 agent trace evaluators based on the Agent GPA framework. The integration went through four review rounds with Samraj Moorjani (Software Engineer at Databricks, MLflow maintainer), with final approval from Avesh C. Singh (Software Engineer at Databricks). It follows the scorer pattern Moorjani established in the DeepEval and RAGAS integrations and extends it to agent trace evaluation, a category that requires reading the full span tree rather than just inputs and outputs.
Josh Reini (TruLens maintainer, Snowflake) reviewed the integration's scorer semantics and validated the trace-aware evaluation behavior. Reini published a companion post on the Snowflake Engineering Blog covering the Agent GPA research and TRAIL benchmark results in depth. A cross-project documentation PR was also merged into the TruLens repository.
Related artifacts:
- Upstream MLflow TruLens PR #19492 (merged)
- TruLens documentation PR #2344 (merged, cross-project)
- Introducing DeepEval, RAGAS, and Phoenix Judges in MLflow (companion blog)